Google App Engine
- Lee Russell (Unlicensed)
- Eduardo Garcia Lopez
- Isomorphic Support
Google App Engine (GAE) is a platform-as-a-service (PaaS) offering from Google, which supports cloud deployment of applications written in Java and other languages, as well as SQL or JPA access to highly scalable storage (both Google CloudSQL and BigTable-based solutions).
SmartClient applications, including those based on the SmartClient Server Framework, can be deployed to GAE and can integrate with Google CloudSQL either via SQLDataSource or via JPA, and can also use Google's BigTable-based storage via JPA.
SmartGWT 4.1d and later now includes sample projects for GAE that already take care of most of the concerns covered in the rest of this article. All the necessary steps to get the sample projects running are described in the readme file for each sample.
Setting up Smart GWT application for GAE
Under the /WEB-INF directory you have to create a file named appengine-web.xml which will hold Google's specific settings. At least, you must set threadsafe flag to "true".
We must take into account that, in GAE “...by default, all files in the WAR are treated as both static files and resource files, except for JSP files, which are compiled into servlet classes and mapped to URL paths, and files in the WEB-INF/ directory, which are never served as static files and always available to the app as resource files.” On the other hand, “App Engine serves static files from dedicated servers and caches that are separate from the application servers.”. This means that all our files, except JSP files and files under WEB-INF, are DUPLICATED both in app server and in dedicated servers. As a typical Smart GWT application consists of many resources, when those resources are duplicated we could exceed the “Code and Static File Storage” quota (currently 1Gb) or go beyond the limit of static files (10.000 per application). To avoid this, we can split our files between static and dynamic resources in appengine-web.xml. This is an example configuration:
appengine-web.xml |
<?xml version="1.0" encoding="UTF-8"?> <threadsafe>true</threadsafe> <static-files> |
PATH_TO_DATA_SOURCE_FILES: is the path to the folder that contains the DataSource definition files, as defined in “project.datasources”, either in server.properties file or in admin console.
MODULE_NAME: The GWT module name, as defined in your GWT module descriptor file.
With this change, we have reduced the size of the GAEDS example application from 140Mb to 100Mb.
Setting up DataSources
To interact with DataSources an additional servlet mapping has to be added to web.xml:
<!-- The IDACall servlet handles all Built-in DataSource operations --> <servlet> <servlet-name>IDACall</servlet-name> <servlet-class>com.isomorphic.servlet.IDACall</servlet-class> </servlet> <servlet-mapping> <servlet-name>IDACall</servlet-name> <url-pattern>/[MODULE_NAME]/sc/IDACall</url-pattern> </servlet-mapping>
There is also the DataSourceLoader servlet:
<!-- The DataSourceLoader servlet returns Javascript representations of the dataSources whose
ID's are passed to it - it is an alternative to using the <loadDS> JSP tag -->
<servlet>
<servlet-name>DataSourceLoader</servlet-name>
<servlet-class>com.isomorphic.servlet.DataSourceLoader</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>DataSourceLoader</servlet-name>
<url-pattern>/[MODULE_NAME]/sc/DataSourceLoader</url-pattern>
</servlet-mapping>
Admin console allows you to configure database access for DataSources that use Smart GWT's built-in SQL engine. To access the admin console you will have to enable the "Tools" module in your GAE application, you can find further information in the admin console documentation, and instructions on setting up in the SgwtEE setup document. As said, you will only be able to configure SQL engine based DataSources, so if you choose Datastore as Data Integration strategy, you will not be able to access the data from admin console.
We have included, in a table below, the required libraries that you will have to include in WEB-INF/lib folder in order to be able to use the admin console. Also, remember to include the iscTaglib.xml in WEB-INF folder, as described in SgwtEE setup document. Finally, there is some extra configuration that you must do in your web.xml.
web.xml configuration when using admin console
You must add these entries in your web.xml when using admin console.
<listener>
<listener-class>com.isomorphic.base.InitListener</listener-class>
</listener>
<servlet>
<servlet-name>Init</servlet-name>
<servlet-class>com.isomorphic.base.Init</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<jsp-config>
<!-- Isomorphic JSP tags -->
<taglib>
<taglib-uri>isomorphic</taglib-uri>
<taglib-location>/WEB-INF/iscTaglib.xml</taglib-location>
</taglib>
</jsp-config>
Data Integration strategies
Using CloudSQL as a SQL DataSource
Using CloudSQL as a JPA DataSource
- Using DataStore as a limited JPA DataSource (severely limited and not recommended)
As a summary, these are the main differences among the three approaches.
CloudSQL Datasource | JPA2 Datasource | Datastore Datasource | |
Example code | gae-cloudSQL | gae-JPA-cloudSQL | gae-JPA-noSQL |
serverType (in server.properties) | sql | no need to specify | no need to specify |
records | SQL rows | java beans | java beans |
record definition (in *.ds.xml) | tableName | schemaBean or beanClassName | schemaBean or beanClassName |
DB Connector | com.isomorphic.sql.SQLDataSource | com.isomorphic.jpa.JPA2DataSource | com.isomorphic.jpa.GAEJPADatasource |
Conector Driver | com.google.appengine.api.rdbms.AppEngineDriver | com.google.appengine.api.rdbms.AppEngineDriver | no need to specify |
Connection config | server.properties* | persistence.xml** | persistence.xml*** |
Connector Library | isomorphic_sql.jar | isomorphic_jpa.jar | isomorphic_jpa.jar |
Other required libraries | commons-codec-1.3.jar commons-collections-3.2.1.jar commons-dbcp-1.2.2.jar commons-fileupload-1.2.1.jar commons-jxpath-1.3.jar commons-lang-2.4.jar commons-pool-1.4.jar isc-jakarta-oro-2.0.6.jar isomorphic_core_rpc.jar isomorphic_sql.jar smartgwt-skins.jar smartgwt.jar smartgwtee.jar velocity-1.7.jar When using tools: commons-cli-1.1.jar commons-lang-2.4.jar hibernate3.jar isomorphic_hibernate.jar isomorphic_tools.jar | commons-codec-1.3.jar commons-collections-3.2.1.jar commons-fileupload-1.2.1.jar commons-jxpath-1.3.jar commons-pool-1.4.jar eclipselink.jar isc-jakarta-oro-2.0.6.jar isomorphic_core_rpc.jar javax.persistence_2.0.4.v201112161009.jar smartgwt-skins.jar smartgwt.jar smartgwtee.jar log4j-1.2.15.jar velocity-1.7.jar When using tools: commons-cli-1.1.jar commons-lang-2.4.jar hibernate3.jar isomorphic_hibernate.jar isomorphic_sql.jar isomorphic_tools.jar | commons-codec-1.3.jar commons-collections-3.2.1.jar commons-fileupload-1.2.1.jar commons-jxpath-1.3.jar commons-pool-1.4.jar isc-jakarta-oro-2.0.6.jar isomorphic_core_rpc.jar isomorphic_jpa.jar isomorphic_js_parser.jar smartgwt-skins.jar smartgwt.jar smartgwtee.jar log4j-1.2.15.jar velocity-1.7.jar When using tools: commons-cli-1.1.jar commons-lang-2.4.jar hibernate3.jar isomorphic_hibernate.jar isomorphic_sql.jar isomorphic_tools.jar |
Comments | You start your project as a GWT + GAE project in eclipse. Then add the required libraries, modify web.xml, create the datasource descriptors, create tables and finally configure “server.properties”. | Setup your eclipse project as specified in this doc. Add the extra libraries, modify web.xml, create the datasource descriptors, configure “persistence.xml”, create the persistent objects, create the tables (maybe automatically). | You start your project as a GWT + GAE project in eclipse. Then add the required libraries, modify web.xml, create the datasource descriptors and create the persistent objects. |
*server.properties: see example below
**persistence.xml: see example below
***persistence.xml is automatically generated when using Datastore.
Terms:
DataSource: “is data-provider-independent description of a set of objects that will be loaded, edited and saved within the user interface of your application”
Record: each datasource access to one kind of record. A record is a set of Fields.
Field: the components of Records. May have types, validators, etc.
DB Connector: each DataSource retrieves Records of one type, accessing a DB via DBConnector
DataBinding: “is the process by which Data Binding-capable UI components can automatically configure themselves for viewing, editing and saving data described by DataSources.”
DataIntegration: “is the process by which a DataSource can be connected to server systems such as SQL DataBases, Java Object models, WSDL web services and other data providers.” It can be server-side or client-side.

Using CloudSQL as a SQL DataSource
This is the primary data integration strategy when working with SmartGWT. It allows you to develop applications that persist their records as tables of a SQL database, being the tables stored by GoogleCloudSQL service. You will usually use the provided connector, "SQLDataSource", but in case you need to extend some of its methods, you will have access to the full power of a SQL database. Also, this solution is very straightforward and easy to use, as you only need to configure the datasource descriptor for each table in a ".ds.xml" file, no need to define the java beans that will access the schema.
To define a Google CloudSQL database as your default database in server.properties you will have to define some properties, as shown below. Take into account that you will have to use the "url" format for the connection (you cannot configure it field by field).
server.properties |
|
where instance_name is the instance Name field, as it appears in the Google APIs Console, and db_name is the name of the SQL database that you created for this project with "CREATE DATABASE db_name".
If you are using the admin console, you will find pre-configured settings as "GoogleCloudSQL".
Using CloudSQL as a JPA2 DataSource
Object Relational Mapping (ORM) frameworks are very popular in the Java community for accessing relational databases. The Eclipse Web Tools Platform offers a robust set of tools to configure and use JPA with an implementation of your choice. With the new Google Plugin for Eclipse 2.6, you can now take advantage of these tools with Cloud SQL and Google App Engine. In any Google Plugin for Eclipse project, JPA can now be enabled and configured as a project facet.
You can find detailed information on how to configure your project to work with JPA2 and CloudSQL in the Google's document "Using Java Persistence API (JPA) with Cloud SQL". The list of required libraries is in the table above (under Data Integration strategies). Finally, using the eclipse "Persistence XML Editor" you will be able to configure properly the connection data, the driver to use, defining the persistent classes, etc in persistence.xml.
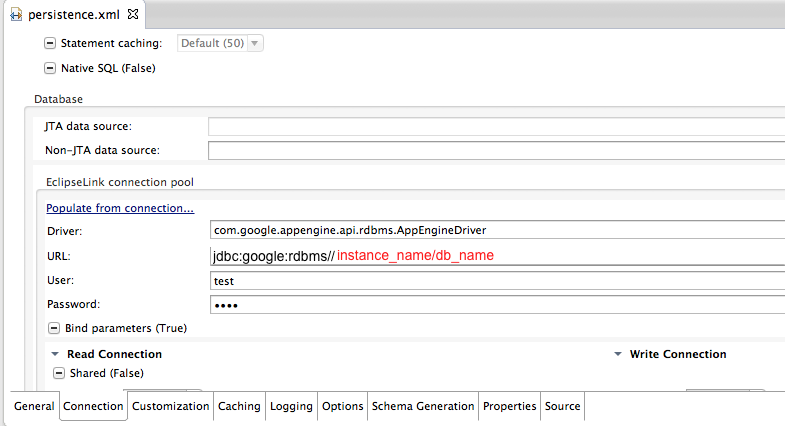
persistence.xml |
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
|
where instance_name is the instance Name field, as it appears in the Google APIs Console, db_name is the name of the SQL database that you created for this project with "CREATE DATABASE db_name", user_name is the name of a database user with access to the tables, and password is the password of the database user.
Using DataStore as a (limited) JPA2 DataSource
Notice that Google's JPA implementation is really wrapping a "NoSQL" type of engine, with severe limitations. We recommend CloudSQL as the first choice.
GAE supports only four types as primary keys:
java.lang.Longjava.lang.Stringjava.lang.Stringwith additional annotationscom.google.appengine.api.datastore.Keynot supported by Smart GWT
Primary key can not be altered after entity is saved.
Entities with primary keys Long or String can not participate in transactions and can not be used in relations. Here is an example how to declare primary key of type String with additional annotations:
import java.io.Serializable;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import org.datanucleus.jpa.annotations.Extension;
@Entity
public class Bar
implements Serializable
{
@Id
@GeneratedValue (strategy = GenerationType.IDENTITY)
@Extension (vendorName = "datanucleus", key = "gae.encoded-pk", value = "true")
private String id;
}
DataSource creation is similar to standard JPA with one difference: property serverConstructor should be set to com.isomorphic.jpa.GAEJPADataSource.
Because of GAE queries limitations this DataSource implementation supports only single inequality criteria in filter.
Only TextMatchStyle.STARTS_WITH filtering mode is supported for text fields.
All queries are case sensitive because GAE does not support upper()/lower() functions in criterias.TextMatchStyle.EXACT is used for all number fields.com.isomorphic.jpa.EMFProviderLMT or com.isomorphic.jpa.EMFProviderNoTransactions should be used as transaction providers (depending whether you use transactions or not).
To participate in a transaction, entities have to belong to the same group.
Note: entities of different type can not participate in a transaction even if these entities have GAE specific primary key (you can not even fetch (SELECT) entities belonging to different groups).
Entities are grouped by establishing owned relationships (where dependent entities are instantiated automatically by the JPA provider) between them. Entities in groups can form a chain of the following sort::
ClassA has reference to ClassB, ClassB has reference to ClassC
But it is impossible to have an entity referencing two other entities:
ClassD has reference to ClassE, ClassD has reference to ClassF
There are no foreign keys - the actual reference is encoded into the primary key of child entity.
GAE datastore does not support many-to-many relationships.
Unidirectional one-to-many relationships work only if the parent has a declaration of List<ChildEntityClass>.
Unidirectional relationships do not work if only the child entity has reference to the parent.
Bidirectional relationship example:
@Entity
public class Country
implements Serializable
{
@Id
@Column (nullable = false)
@GeneratedValue (strategy = GenerationType.IDENTITY)
@Extension (vendorName = "datanucleus", key = "gae.encoded-pk", value = "true")
private String countryId;
@OneToMany
private List cities;
//....
}
@Entity
public class City
implements Serializable
{
@Id
@Column (nullable = false)
@GeneratedValue (strategy = GenerationType.IDENTITY)
@Extension (vendorName = "datanucleus", key = "gae.encoded-pk", value = "true")
private String cityId;
// This is fake column - it is calculated by provider and is not saved.
// Actual reference to parent entity is encoded in primary key.
@Column (nullable = false)
@Extension (vendorName = "datanucleus", key = "gae.parent-pk", value = "true")
private String countryId;
@ManyToOne (fetch=FetchType.LAZY)
private Country country;
//....
}
Note: GAE does not support FetchType.EAGER.
With Unowned Relationships (when you save parent's primary key as simple child's property) you can model unsupported relationships. But this approach has drawbacks:
- related entities are not instantiated automatically
- transactions can not be used
- you have to manually keep track of changes in case of bidirectional relationship
Additional information
The SmartGWT Pro/EE Evaluation now includes a sample GAE project, including automatic execution of CRUD operations via the built-in JPADataSource.